Unfortunately the Russian database of the national standards (GOSTs) does not enable to get files as .pdf , but only as separate images (which are even not directly available).
So we can’t even download the texts, it’s a pity. I’ve made a simple Python script to address this problem, because it’s far better to read and explore a printed copy.
Script uses some libraries, you can install them by running pip install img2pdf pypdf2 requests
It was tested in Python 2.7.
Usage:
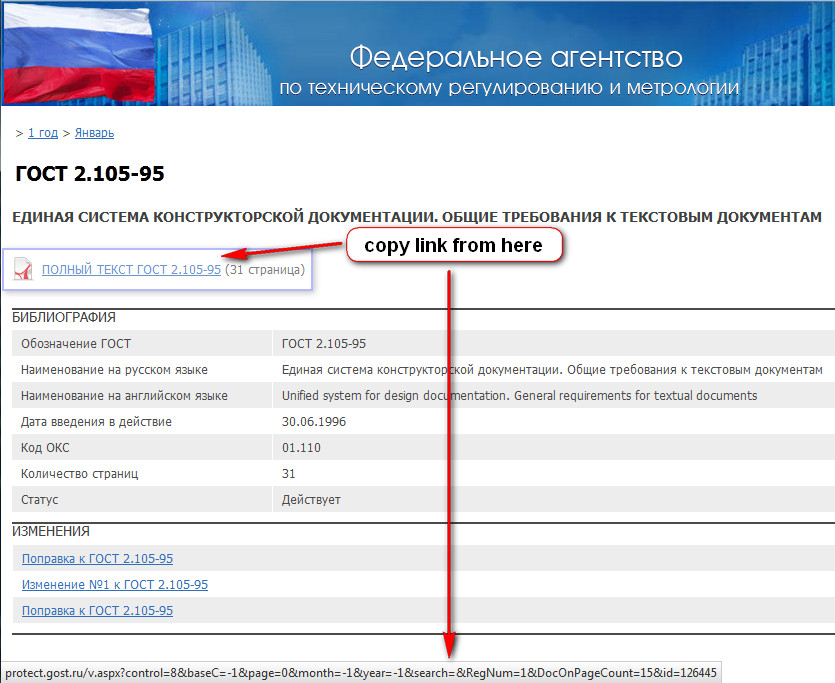
- Find the standard you want to download from site protect.gost.ru
- Get the link, in the example it is
http://protect.gost.ru/v.aspx?control=8&baseC=-1&page=0&month=-1&year=-1&search=&RegNum=1&DocOnPageCount=15&id=126445 - Replace the link in the script
- Run the script
python gostdl.py - In the same folder you will get separate pages of document in .pdf and .jpg format as well as merged document in
document.pdf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |